His research interests lie in geometric generative modeling and its applications to multimodal foundation models, world models, embodied AI, and AI for health.
Selected publications are highlighted. (*Equal contribution. ✝Project lead. ✉Corresponding author.)
EvoVLA: Self-Evolving Vision-Language-Action Model
Zeting Liu*,
Zida Yang*,
Zeyu Zhang*✝,
Hao Tang✉ ECCV 2026
EvoVLA mitigates long-horizon stage hallucination with self-supervised rewards, pose-grounded exploration, and selective memory, achieving substantially higher success on Discoverse-L and strong Sim2Real robustness.
MobileVLA-R1: Reinforcing Vision-Language-Action for Mobile Robots
Ting Huang*,
Dongjian Li*,
Rui Yang*,
Zeyu Zhang*✝,
Zida Yang,
Hao Tang✉ ECCV 2026
MobileVLA-R1 enables robust real-world quadruped control by unifying language reasoning and continuous action through structured CoT alignment and GRPO training.
ReMoMask: Retrieval-Augmented Masked Motion Generation
Zhengdao Li*,
Siheng Wang*,
Zeyu Zhang*✝,
Hao Tang✉ ECCV 2026
ReMoMask is a retrieval-augmented masked text-to-motion generation model that enhances retrieval precision, improves temporal-spatial alignment, and achieves state-of-the-art performance on motion generation benchmarks.
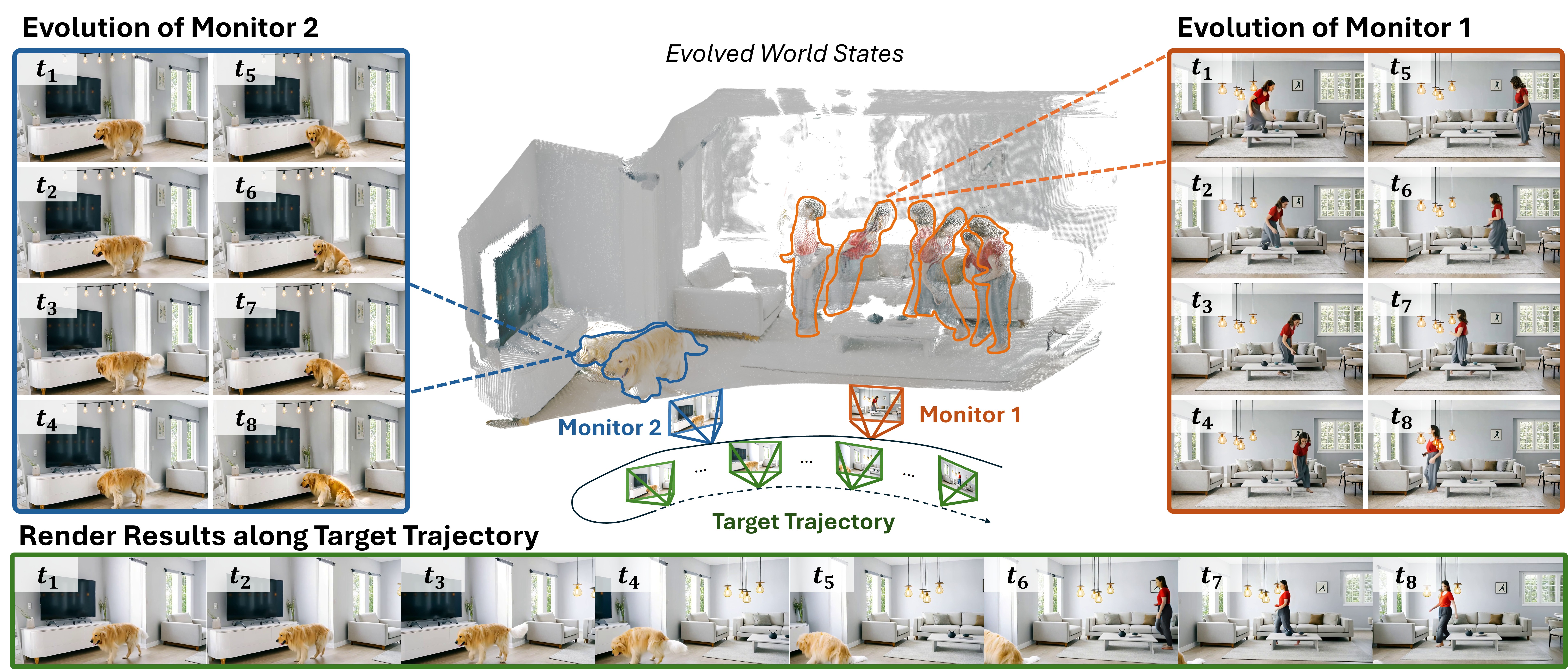
LiveWorld: Simulating Out-of-Sight Dynamics in Generative Video World Models
Zicheng Duan*,
Jiatong Xia*,
Zeyu Zhang*,
Wenbo Zhang,
Gengze Zhou,
Chenhui Gou,
Yefei He,
Feng Chen,
Xinyu Zhang,
Lingqiao Liu✉ ECCV 2026
LiveWorld solves out-of-sight dynamics in video world models by continuously simulating unseen objects, enabling persistent, consistent 4D world evolution.
VLA-R1: Enhancing Reasoning in Vision-Language-Action Models
Angen Ye*,
Zeyu Zhang*,
Boyuan Wang,
Xiaofeng Wang,
Dapeng Zhang,
Zheng Zhu✉ ECCV 2026
VLA-R1 enhances vision-language-action models with RL-based reasoning, chain-of-thought supervision, and strong execution, achieving superior performance across benchmarks, simulation, and real-world tasks.
VolSplat: Rethinking Feed-Forward 3D Gaussian Splatting with Voxel-Aligned Prediction
Weijie Wang*,
Yeqing Chen*,
Zeyu Zhang,
Hengyu Liu,
Haoxiao Wang,
Zhiyuan Feng,
Wenkang Qin,
Feng Chen,
Zheng Zhu,
Donny Y. Chen,
Bohan Zhuang ECCV 2026
VolSplat replaces pixel-aligned with voxel-aligned Gaussian prediction, improving multi-view consistency, geometry, and rendering quality while achieving state-of-the-art performance.
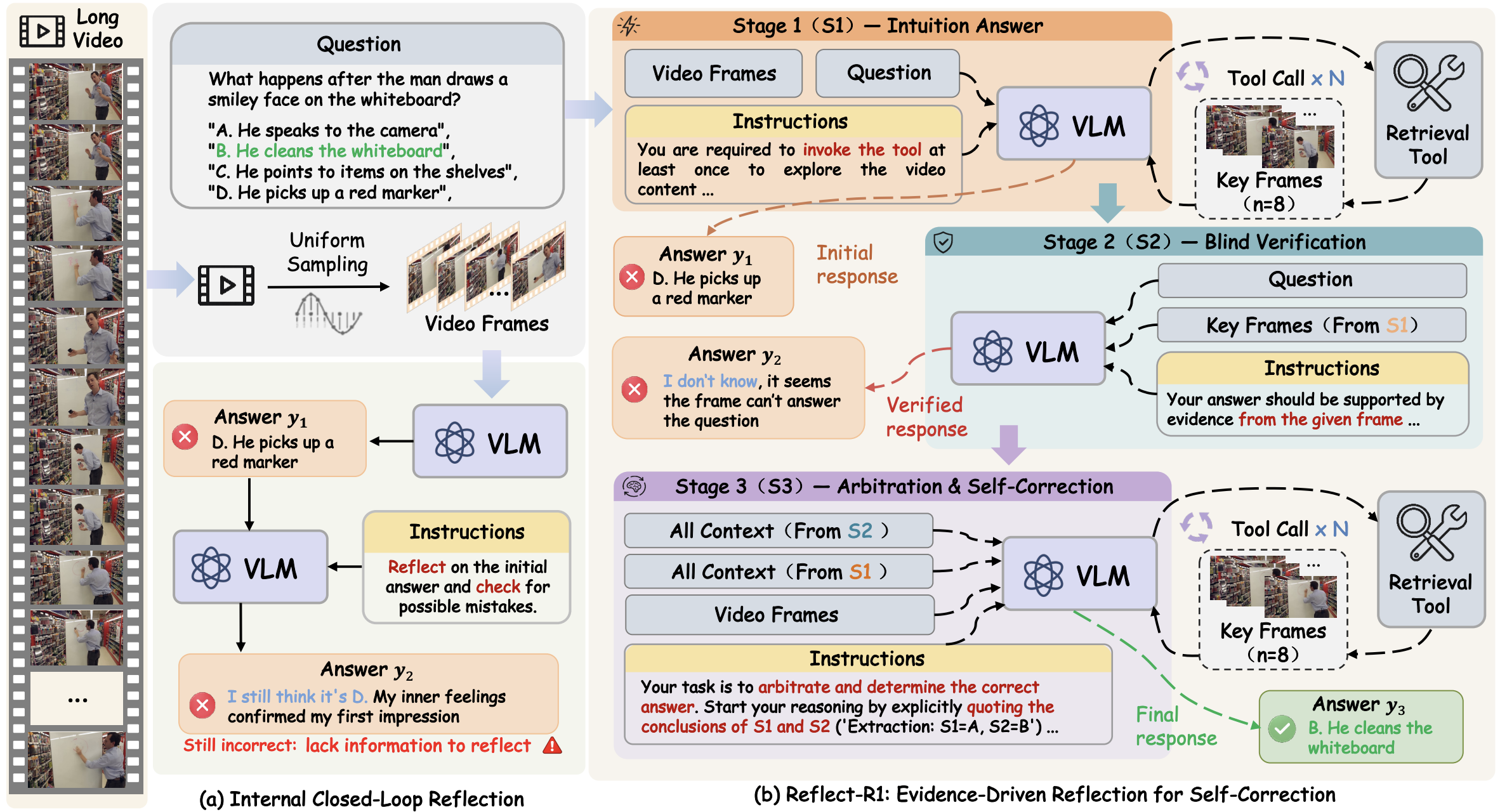
Reflect-R1: Evidence-Driven Reflection for Self-Correction in Long Video Understanding
Shuimu Chen,
Yuteng Chen,
Yuanshen Guan,
Zebang Cheng
Zeyu Zhang,
Shengqian Qin,
Bin Xia,
Jiaran Li,
Wenming Yang,
Fei Ma
ECCV 2026
Reflect-R1 improves long-video understanding through evidence-based self-correction, stage-decoupled reinforcement learning, and large-scale training, reducing hallucinations significantly.
Code2Worlds: Empowering Coding LLMs for 4D World Generation
Yi Zhang*,
Yunshuang Wang*,
Zeyu Zhang*✝,
Hao Tang✉ ICML 2026
Achieving spatial intelligence requires moving beyond visual plausibility. We propose Code2Worlds, a language-to-simulation framework with dual-stream generation and physics-aware refinement, achieving superior dynamic fidelity and performance on Code4D benchmarks.
Position: RL Should Be Used to Adjust Foundation Models, NOT Abused
Ting Huang*,
Zeyu Zhang*✝,
Hao Tang✉ ICML 2026 Position
This position paper argues reinforcement learning should adjust foundation models after pretraining, not serve as default capability creation, emphasizing targeted refinement, reward minimalism, and disciplined deployment.
World-R1: Reinforcing 3D Constraints for Text-to-Video Generation
Weijie Wang,
Xiaoxuan He,
Youping Gu,
Yifan Yang,
Zeyu Zhang,
Yefei He,
Yanbo Ding,
Xirui Hu,
Donny Y. Chen,
Zhiyuan He,
Yuqing Yang,
Bohan Zhuang ICML 2026
Video foundation models lack geometric consistency. We propose World-R1, aligning generation with 3D constraints via reinforcement learning, improving structural coherence while preserving visual quality and scalability.
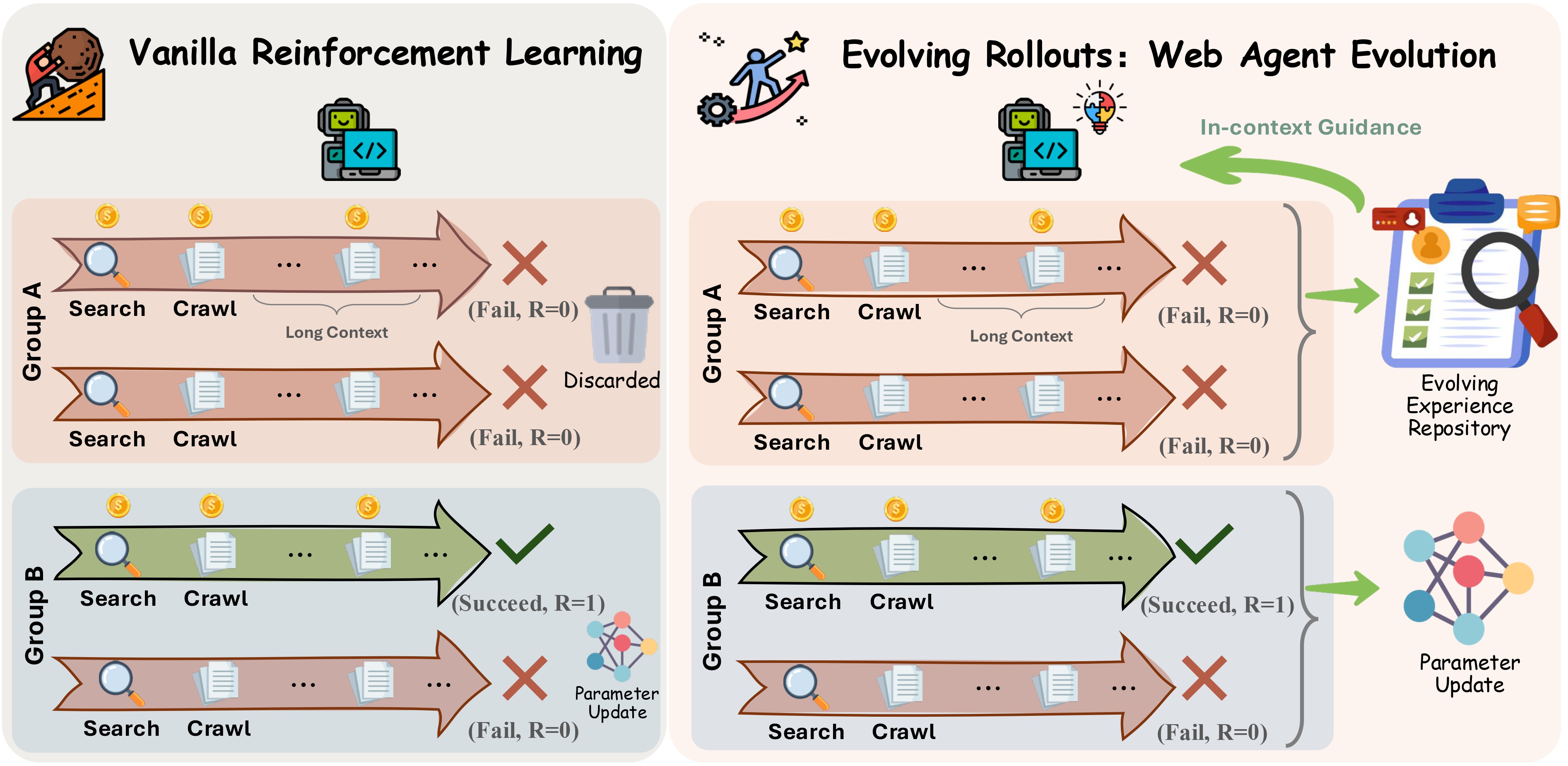
EVOLVING ROLLOUTS: Harnessing Historical Experience for Web Agent Evolution in Reinforcement Learning
Sinuo Wang,
Piaohong Wang,
Tianrui Qin,
Maojia Song,
Qianben Chen,
Qiexiang Wang,
Gengze Zhou,
Zeyu Zhang,
He Zhu,
Dingfeng Shi,
Yutong Xie,
Minghao Liu,
Jiaheng Liu,
Ge Zhang,
Jiawei Ma,
Yuchen Eleanor Jiang,
Qi Wu,
Wangchunshu Zhou ICML 2026
Agentic RL for web search is costly and inefficient. We propose Evolving Rollouts, distilling trajectories into in-context guidance, improving sample efficiency and enabling smaller models to match larger models.
Group Cognition Learning: Making Everything Better Through Controlled Two-Stage Agents Collaboration
Chunlei Meng,
Pengbin Feng,
Rong Fu,
Hoi Leong Lee,
Xiaojing Du,
Zhaolu Kang,
Zeyu Zhang,
Weilin Zhou,
Chun Ouyang,
Zhongxue Gan ICML 2026
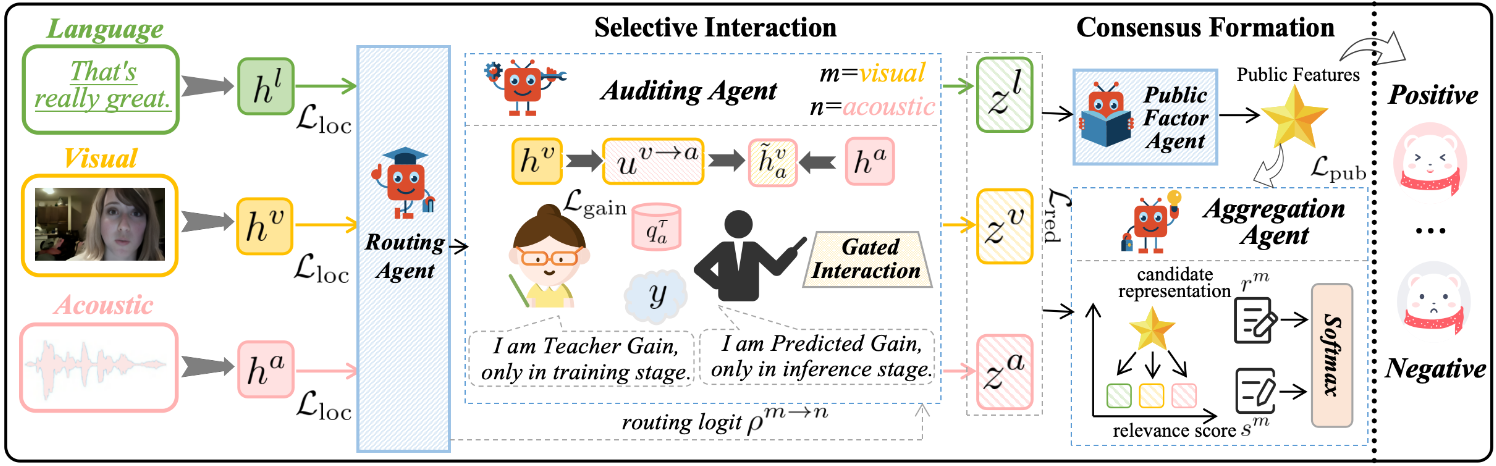
Centralized multimodal learning suffers from modality dominance and spurious coupling. We propose Group Cognition Learning, a two-stage collaboration framework improving interaction, specialization, and achieving state-of-the-art multimodal prediction performance.
GeoWorld: Geometric World Models Zeyu Zhang,
Danning Li,
Ian Reid,
Richard Hartley
CVPR 2026
GeoWorld introduces hyperbolic energy-based world models with geometric reinforcement learning, enabling stable long-horizon visual planning and hierarchical reasoning, outperforming V-JEPA-2 on CrossTask and COIN benchmarks.
Decoupling Defense Strategies for Robust Image Watermarking
Jiahui Chen,
Zehang Deng,
Zeyu Zhang,
Chaoyang Li,
Lianchen Jia,
Lifeng Sun CVPR 2026
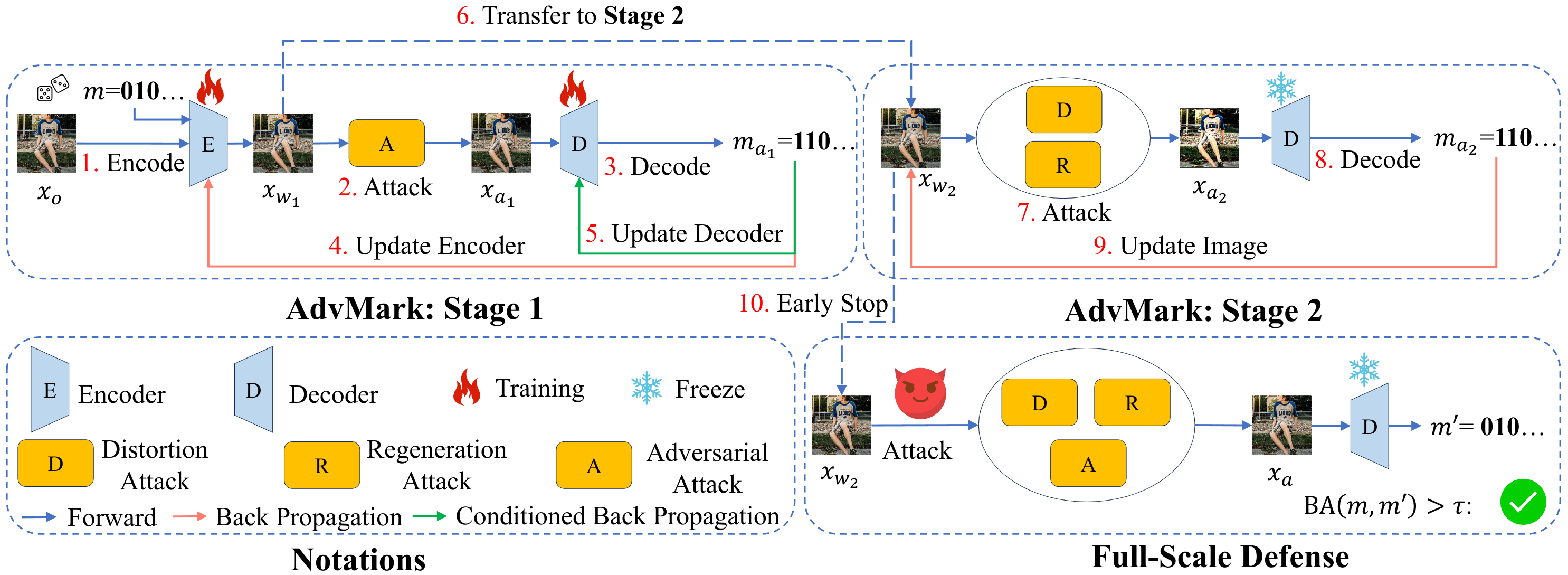
Deep learning watermarking is vulnerable to advanced attacks. We propose AdvMark, a two-stage framework improving robustness and quality by decoupling adversarial training and image optimization strategies.
StereoAdapter: Adapting Stereo Depth Estimation to Underwater Scenes
Zhengri Wu*,
Yiran Wang*,
Yu Wen*,
Zeyu Zhang*✝,
Biao Wu,
Hao Tang✉ ICRA 2026
Underwater stereo depth estimation enables accurate 3D geometry for robotics. We propose StereoAdapter, combining LoRA-adapted monocular encoders with stereo refinement, achieving robust improvements on benchmarks.
VaseVQA-3D: Benchmarking 3D VLMs on Ancient Greek Pottery
Nonghai Zhang*,
Zeyu Zhang*✝,
Jiazi Wang*,
Yang Zhao,
Hao Tang✉ ICLR 2026
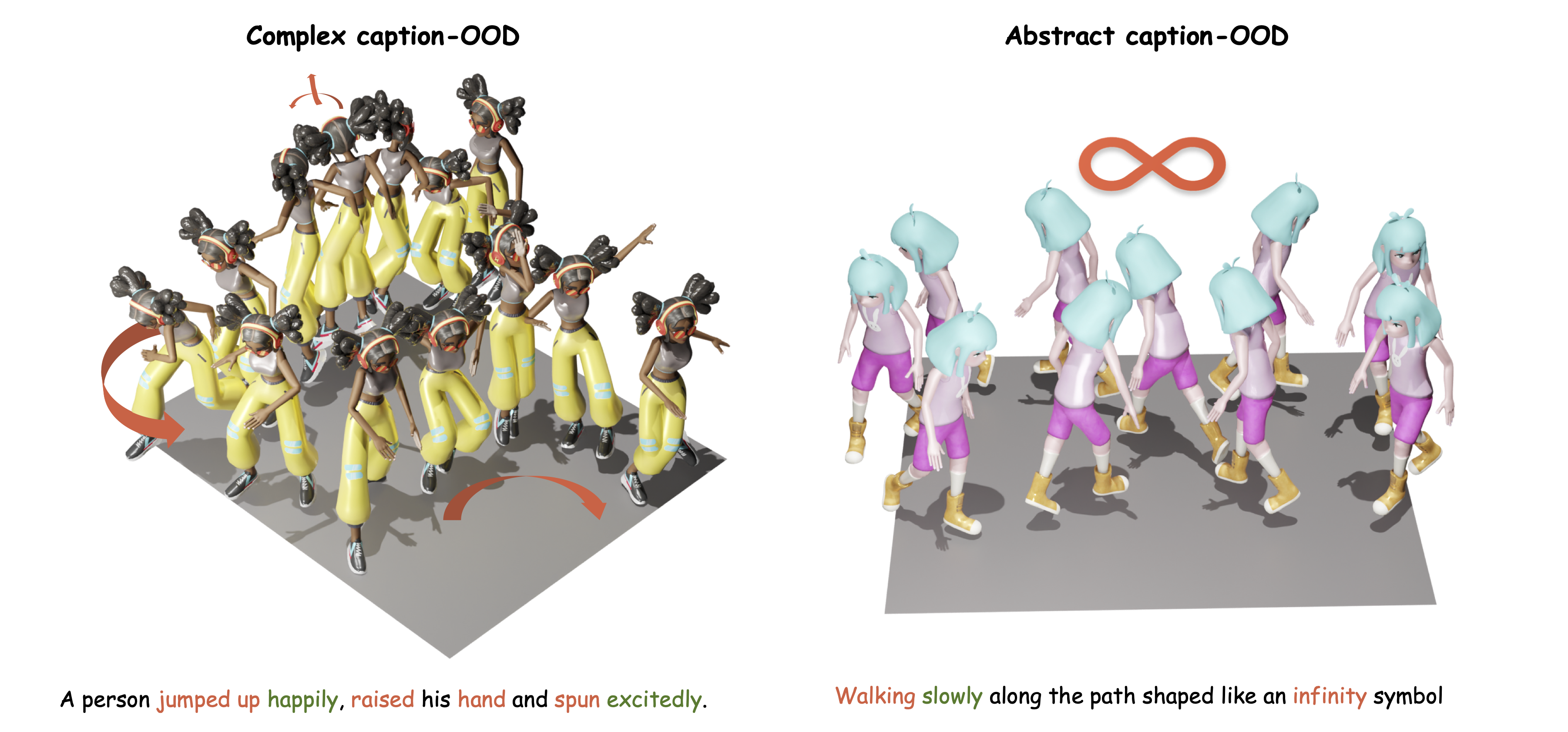
VaseVQA-3D introduces the innovative 3D visual question-answering dataset for ancient Greek pottery, featuring 664 annotated vase models, while VaseVLM is a domain-adaptive vision-language model trained for cultural heritage analysis.
Motion-R1: Enhancing Motion Generation with Decomposed Chain-of-Thought and RL Binding
Runqi Ouyang,
Haoyun Li,
Zhenyuan Zhang,
Xiaofeng Wang,
Zeyu Zhang,
Zheng Zhu,
Guan Huang,
Sirui Han,
Xinggang Wang
ICLR 2026
Motion-R1 combines decomposed Chain-of-Thought reasoning with reinforcement learning to better capture temporal causality in text-to-motion generation, achieving state-of-the-art quality and alignment across benchmarks.
HiVid: LLM-Guided Video Saliency For Content-Aware VOD And Live Streaming
Jiahui Chen,
Bo Peng,
Lianchen Jia,
Zeyu Zhang,
Tianchi Huang,
Lifeng Sun ICLR 2026
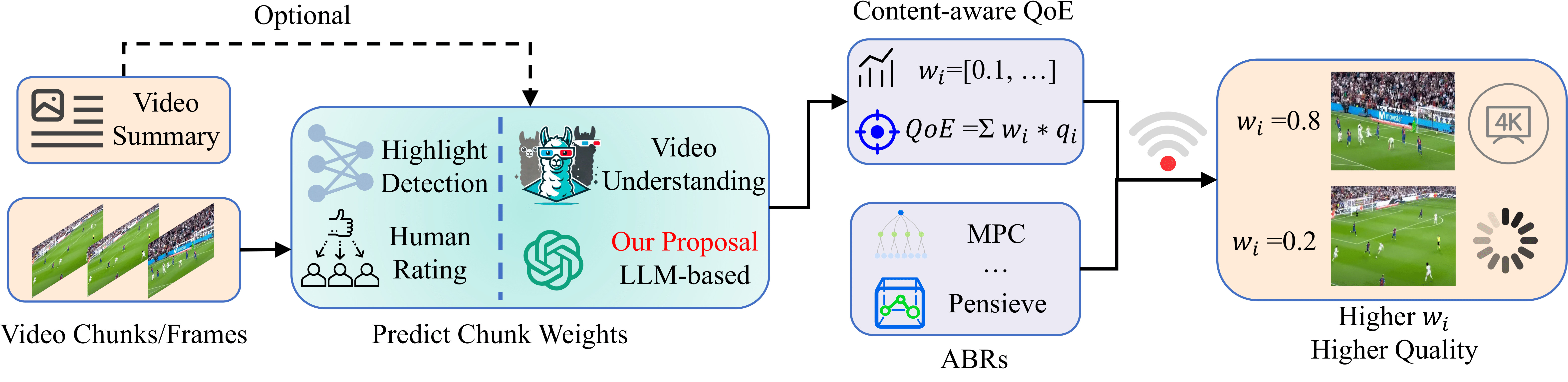
Content-aware streaming requires chunk-level importance weights. We propose HiVid, using LLMs as human proxies with perception, ranking, and prediction modules, improving QoE prediction for VOD and live streaming.
FlashMo: Geometric Interpolants and Frequency-Aware Sparsity for Scalable Efficient Motion Generation Zeyu Zhang*,
Yiran Wang*,
Danning Li*,
Dong Gong,
Ian Reid,
Richard Hartley
NeurIPS 2025
FlashMo introduces a geometric factorized interpolant and frequency-sparse attention, enabling scalable efficient 3D motion diffusion. Experiments show superior quality, efficiency, and scalability over state-of-the-art baselines.
FPSAttention: Training-Aware FP8 and Sparsity Co-Design for Fast Video Diffusion
Akide Liu*,
Zeyu Zhang*,
Zhexin Li,
Xuehai Bai,
Yuanjie Xing,
Yizeng Han,
Jiasheng Tang,
Jichao Wu,
Mingyang Yang,
Weihua Chen,
Jiahao He,
Yuanyu He,
Fan Wang,
Gholamreza Haffari,
Bohan Zhuang NeurIPS 2025Spotlight
FPSAttention is a training-aware FP8 quantization and sparsity co-design for video diffusion models that achieves up to 7.09x kernel speedups and 4.96× E2E speedups without quality loss by aligning 3D tile granularity, denoising-step adaptation, and hardware-efficient kernels.
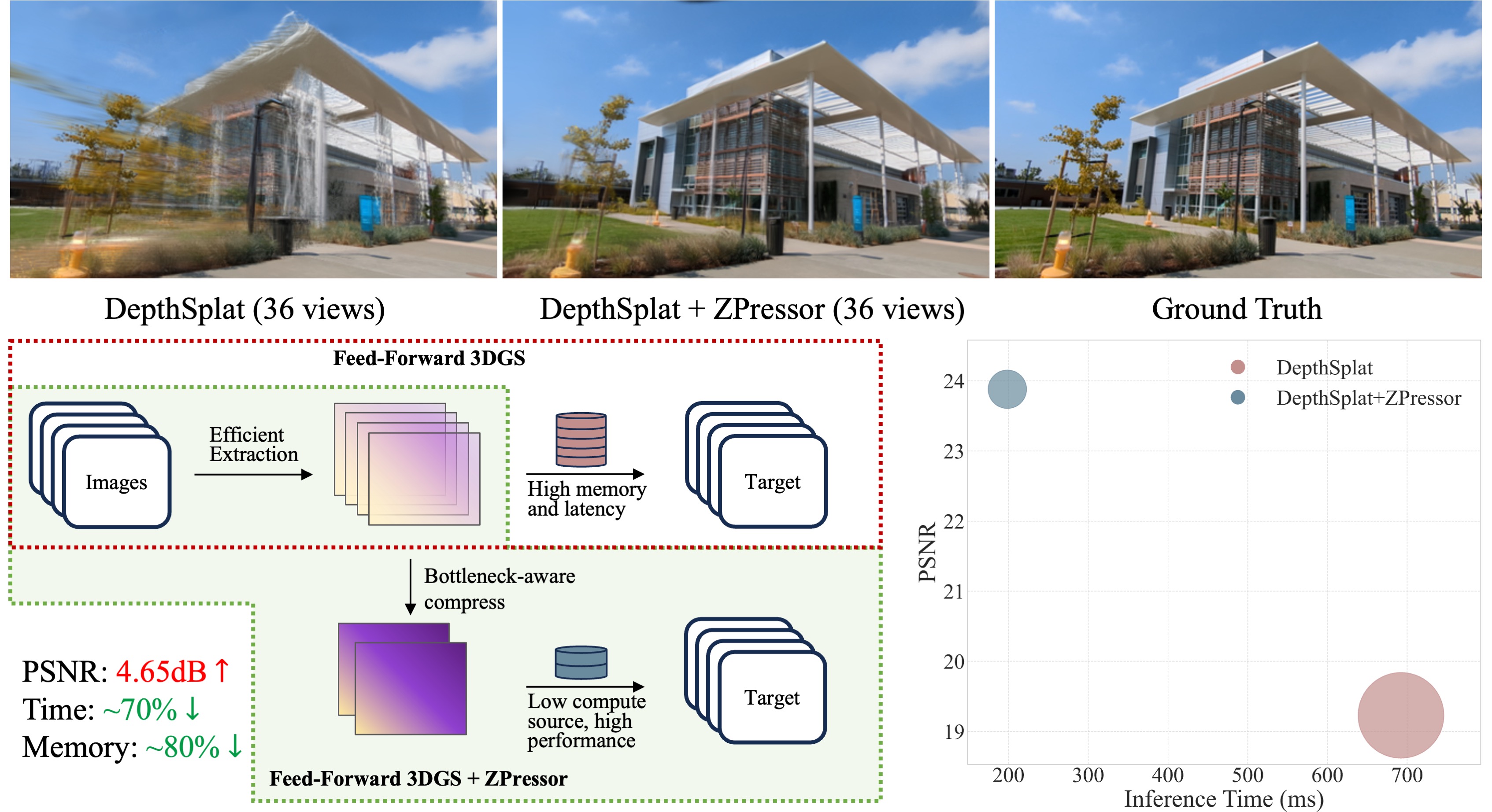
ZPressor: Bottleneck-Aware Compression for Scalable Feed-Forward 3DGS
Weijie Wang,
Yuedong Chen,
Zeyu Zhang,
Duochao Shi,
Akide Liu,
Bohan Zhuang NeurIPS 2025
Feed-forward 3D Gaussian Splatting scales poorly with many views. We propose ZPressor, a lightweight module compressing multi-view inputs, improving performance and enabling efficient high-resolution rendering.
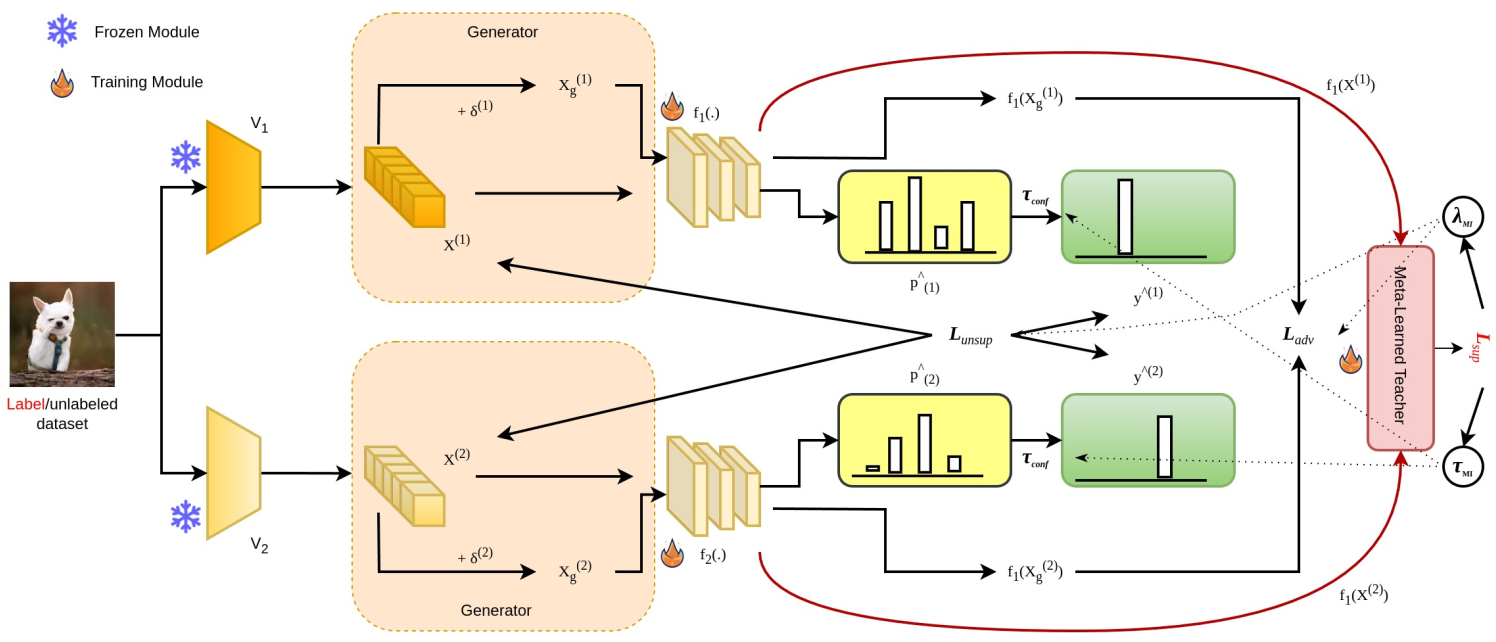
TRiCo: Triadic Game-Theoretic Co-Training for Robust Semi-Supervised Learning
Hongyang He,
Xinyuan Song,
Yangfan He,
Zeyu Zhang,
Yanshu Li,
Haochen You,
Lifan Sun,
Wenqiao Zhang NeurIPS 2025
TRiCo introduces a triadic game-theoretic co-training framework with two students, a meta-learned teacher, and an adversarial generator, leveraging mutual information pseudo-labeling to achieve state-of-the-art semi-supervised learning performance.
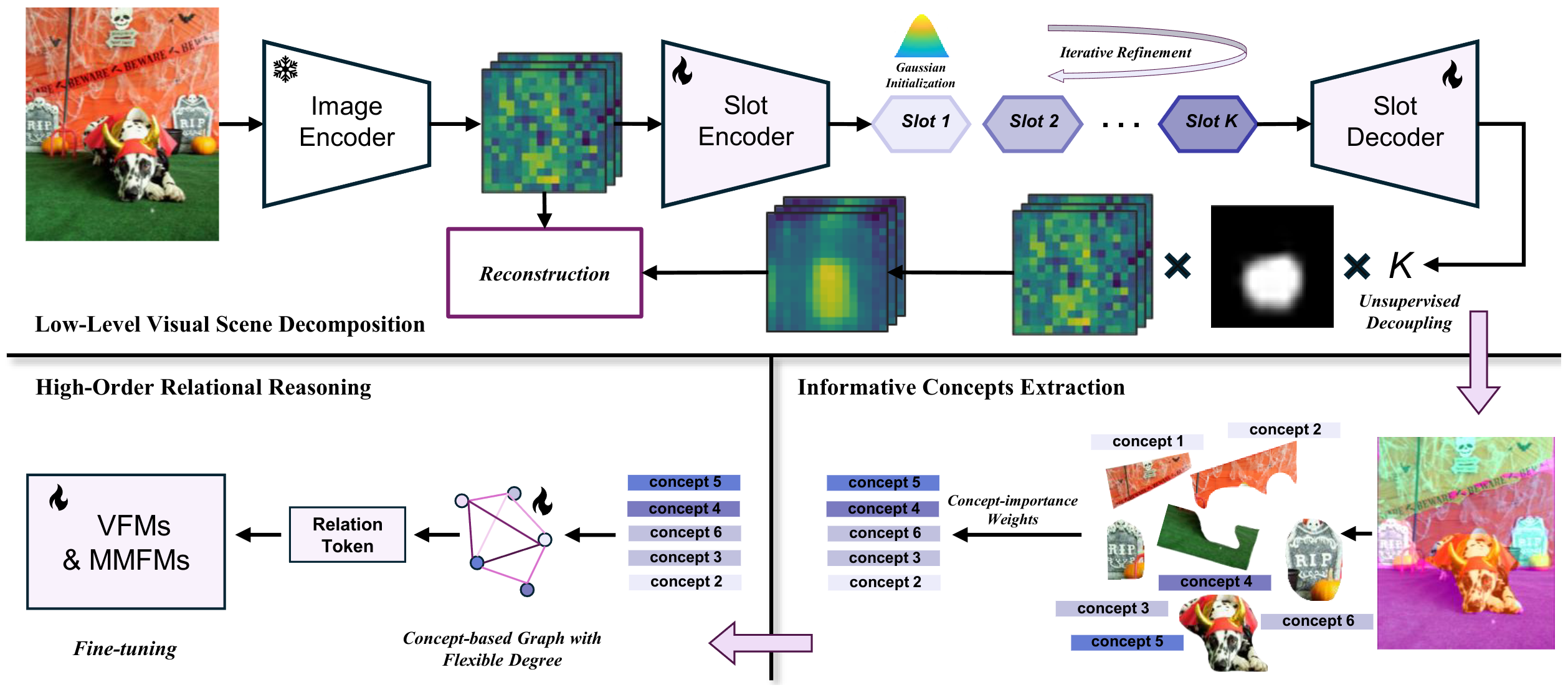
OCRT: Boosting Foundation Models in the Open World with Object-Concept-Relation Triad
Luyao Tang,
Chaoqi Chen,
Yuxuan Yuan,
Zeyu Zhang,
Yue Huang,
Kun Zhang
CVPR 2025
Foundation models struggle with distribution shifts and weak supervision. We propose OCRT, a framework extracting high-level concepts and relations, enhancing SAM and CLIP generalizability in diverse tasks.
Efficient Learning With Sine-Activated Low-rank Matrices
Yiping Ji,
Hemanth Saratchandran,
Cameron Gordon,
Zeyu Zhang,
Simon Lucey
ICLR 2025
Low-rank decomposition improves efficiency but reduces accuracy. We propose a sinusoidal-enhanced framework increasing effective rank, boosting performance while preserving compactness across transformers, LLMs, NeRF, and 3D modeling.
Motion Mamba: Efficient and Long Sequence Motion Generation Zeyu Zhang*,
Akide Liu*,
Ian Reid,
Richard Hartley,
Bohan Zhuang,
Hao Tang
ECCV 2024
Human motion generation is a key goal in generative computer vision. We propose Motion Mamba, using state space models with Hierarchical Temporal and Bidirectional Spatial blocks, achieving improved FID and faster motion modeling.
Research Assistant La Trobe University Apr 2024 - Present
3D generation and AI for Heath, working with Dr. Yang Zhao (La Trobe University).
Research Assistant Monash University Feb 2024 - May 2024
3D/4D generative learning, specifically focusing on text-guided human motion and avatar generation, working with Prof. Reza Haffari (Monash University), and Prof. Bohan Zhuang (ZJU, Monash University).
Bachelor of Science (Advanced) (Honours) The Australian National University (ANU) Jul 2021 - Jun 2025
Major: Computer Science, Minor: Mathematics, First Class Honours (H1), GPA: 6.656/7
Visiting Student Imperial College London Jul 2022
Quantitative Sciences Research Institute (QSRI)